
What would you say if I told you there is a app on the market that tell you if you have a hotdog or not a hotdog. It is very good and I do not want to work on it any more. You can hire someone else.
Jian-Yang, 2017
Hotdog / not hotdog
I have been looking to get into Deep Learning for a while now. It’s been a hugely hot topic for years now, and the libraries seem to be maturing fast. However, most initial tutorials I’ve found seem a little… boring. I mean, it’s great to be able to recognize digits or tell cats from dogs, but what if I could tell hotdogs from not hotdogs? Maybe I’d package that into iOS and Android apps. And I could sell to Periscope and become really rich, not like that conman Bachmann!!
So I embarked on just that journey: to build the best hotdog/no hotdog classifier a Data Scientist with no prior experience in Deep Learning can build. I started with getting input data, continued through building my first Convolutional Neural Network and ended up building a pretty decent classifier using some cutting edge concepts. Join me in this series of posts if you want to do the same!
AI, Machine Learning, Deep Learning
Since you are reading this blog post, you probably are someone with a technical background in the Data Science sphere. If you already know this, bear with me because I’m going to frame the discussion a bit just so we are in the same page. You can also skip to the next section.
Artificial Intelligence, AI, is a very poorly defined term. If you Google it you will get ‘the theory and development of computer systems able to perform tasks normally requiring human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.’ If you consider that for a second, it’s an ever receding horizon: as soon as some cognitive task (addition, looking up references, recognizing digits, translation..) is performed by machines routinely, it stops being AI because it isn’t the exclusive province of humans anymore. So it doesn’t seem very useful.
Machine Learning, ML, can be considered a subset of AI. It’s just a set of algorithms that allow computers to learn rules from data. You get some tagged examples, give them to the algorithm, and voila, you have a digit recognizer, or a churn predictor, or whatever else you want (that’s actually supervised machine learning, but let’s not get into that).
Finally, Deep Learning (DL), which is what most general publications are talking about these days when they talk about AI. It’s a subset of ML. It uses Neural Networks, or multilayer perceptrons. These are just mathematical machines that can approximate any function, for example one that eats images of digits (matrices of 28x28 pixels) and spits out one of ten values indicating which of the digits it is.
So, if it’s just that, how come it’s eating the world? Well, a number of trends have coalesced to push DL into extraordinary results. Some algorithmic advances, the unprecedented availability of data brought by the move of everyday life to the Internet and advances in computer power (especially, training of neural networks on GPUs) have enabled DL to outperform traditional approaches in a lot of fields: especially image classification, but also image segmentation, translation, sentiment analysis, recommendations and a lot more. The hope is that many more tasks that until now were the exclusive of humans can be automated in the near future (remember that receding horizon?), including driving a car. That last one has been overhyped in my opinion, but the power and applicability of the technique is undeniable.
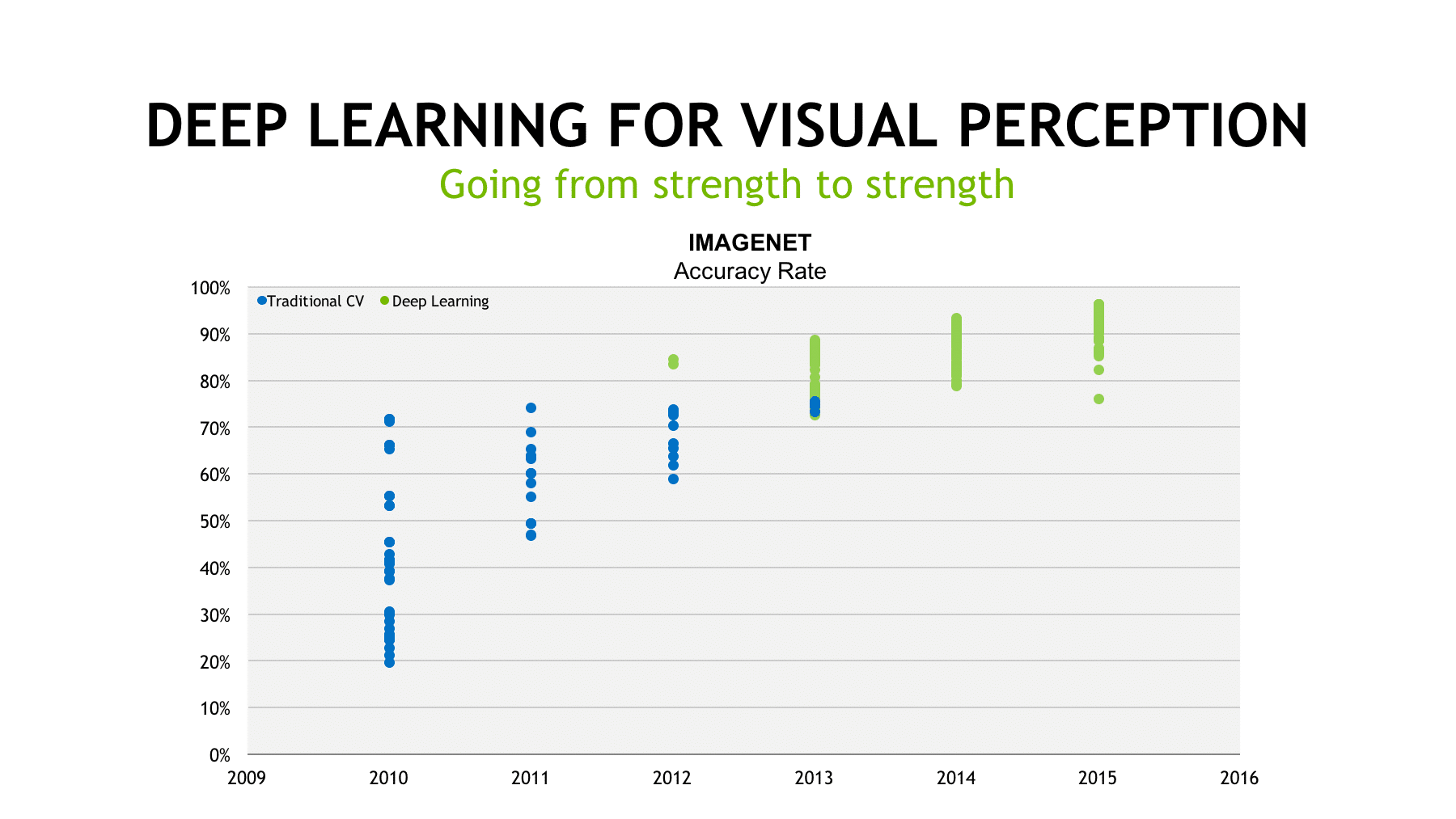
The current frenzy probably started with the ImageNet competition of 2012. ImageNet was a competition held every year in which academic teams would compete to write the algorithm that would recognize the most images from a huge standardized set. In 2012, two teams entered the competition using DL techniques and bested everyone else. As you can see in the graph, it didn’t take long before everyone was using it to get unprecented results. Now it’s everywhere, and we are finally going to be part of the action.
This project
So let’s recapitulate: we are going to build a computer program that, after being shown enough examples of hot dogs and things that are not hotdogs, will learn to tell between them. I’ll guide you through each step and explain everything you need. The only prerequisites are some Python programming and a bit of general ML background.
The pieces we need are:
- Training images: that’s what we are here for!
- A Deep Learning Framework: Keras. I’d recommend installing it using conda.
- A computer with an NVIDIA GPU: not technically necessary, but in fact it is.
The reference environment we’ll be using is Linux. I honestly think it’s the platform to use for data science, but if you only have Mac or Windows, do not worry. Most of the commands we’ll be using are available in Mac through homebrew, and now even in Windows through the Windows Subsystem for Linux. I won’t be covering that, but it should be easy enough.
Today, we’ll get some training images. It’s going to be a bit long, but it’ll be worth it. At the end we’ll have what we need to build our revolutionary hotdog/nohotdog app. Not only that; we’ll have a method that will be applicable for getting training images for any classifier in the ImageNet vocabulary.
ImageNet
We need a set of images that are hotdogs and a set of images that are not hotdogs in order to be able to train our algorithm. For that we can use the ImageNet set of tagged images. The thing is, ImageNet contains more than a million images totalling around 100GB. Not only would that take a long time to download: it would be prohibitively costly to train. We are going to download only a part of it for now.
For that, we need to understand how ImageNet is structured. It is based upon WordNet, a lexical database of English. WordNet contains nouns, verbs, adjectives and adverbs grouped into synsets (sets of synonyms), but ImageNet contains images corresponding only to the nouns. Each synset is identified by its wnid (WordNet id). There are actually three hotdog synsets: n07676602, n07697537, and n10187710.
ImageNet doesn’t own the images, so they only provide them after a registration and a request promising to use them for non-commercial research and/or educational use. However, they do provide the image urls freely, so we are going to use our downloader to get them. We will need to get the urls first.
# We use the requests module to download, and os to check files.
import requests
import os
def download(url):
'''
Download a single freely available file if it's not already in the current directory.
'''
filename = url.split('/')[-1]
# Do not re-download: the damn website is sloooooow
if not os.path.exists(filename):
# Download and write to file
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
%%time
# Retrieve the list of terms from the imagenet website:
download('http://image-net.org/archive/words.txt')
!head -n 5 words.txt
n00001740 entity
n00001930 physical entity
n00002137 abstraction, abstract entity
n00002452 thing
n00002684 object, physical object
CPU times: user 40 ms, sys: 4 ms, total: 44 ms
Wall time: 1min 1s
# Build a dictionary of wnids and terms: as easy as one dict comprehension
with open('words.txt') as f:
wnids = {line.split()[0]: line.split()[1] for line in f.readlines()}
wnids are overlapping, that is, there are general terms and more specific terms that are contained within them (hyponyms). The easiest way to deal with this is to just get the urls for the images we want and deduplicate them.
We need two things: A list of all the image urls and a list of all hotdog urls. The ImageNet website has an api for retrieving the urls that correspond to a wnid, so we’ll use that for the hotdog urls.
import matplotlib.pyplot as plt
from IPython.display import Image, display
%matplotlib inline
def urls_from_wnid(wnid):
'''Get all image urls corresponding to a single WordNet (noun) ID'''
# The requests library encodes parameters in urls for us:
response = requests.get('http://www.image-net.org/api/text/imagenet.synset.geturls', params={'wnid' : wnid})
urls = response.content.decode('latin1').splitlines()
return urls
first_five_images = [Image(url=url, width=400) for url in urls_from_wnid('n07697537')[:5]]
display(*first_five_images)





We see here a first problem: some of the links are broken. Don’t worry, there are enough for our purposes.
This would work also to get all images, but it would extremely slow because we are making over 80000 requests. Also because the damn imagenet site is sloooooooow. What we are going to do is use this technique to get all hotdog urls and then substract those from the complete list of urls, which is freely available from the ImageNet website as a .tgz file.
%%time
hotdog_wnids = {wnid for wnid, term in wnids.items() if 'hot' in term and 'dog' in term}
hotdog_urls = {url for wnid in hotdog_wnids for url in urls_from_wnid(wnid)} # sloooooooooooooooow
len(hotdog_urls)
CPU times: user 16 ms, sys: 4 ms, total: 20 ms
Wall time: 43 s
%%time
imagenet_fall11_urls = 'http://image-net.org/imagenet_data/urls/imagenet_fall11_urls.tgz'
download(imagenet_fall11_urls)
CPU times: user 1.48 s, sys: 1.22 s, total: 2.7 s
Wall time: 1min 11s
Now we need to build the list of all urls. We just read the file, using the tarfile module, and fill the list.
%%time
import tarfile
tf = tarfile.open('imagenet_fall11_urls.tgz')
# Shortcut: I know it contains a single file, so we extract the first member.
content = tf.extractfile(tf.getmembers()[0])
wnids_urls = []
for line in content:
try:
# Split a single line at a tab
wnid, url = line.decode('utf-8')[:-1].split('\t')
except:
# There are a few urls that fail; too few to worry
# If you want to check them out, uncomment the following line
# print(line)
pass
wnids_urls.append((wnid, url))
len(wnids_urls)
CPU times: user 38 s, sys: 2.29 s, total: 40.2 s
Wall time: 40.4 s
Aaaand we have it! Just need to dedup the urls and substract the hotdog urls.
# Some urls might be duplicated; dedup by using a set comprehension
# You can tell I really like comprehensions in python, can't you?
all_urls = {url for wnid, url in wnids_urls}
# We already have the hotdog urls from before
other_urls = all_urls - hotdog_urls
print((len(all_urls), len(hotdog_urls), len(other_urls)))
(13023002, 1218, 13021790)
Aaaaand from that, we are going to choose a sample of hotdogs and not hotdogs!
import random
from sklearn.model_selection import train_test_split
random.seed(42)
hotdogs_sample = random.sample(hotdog_urls, 1216) # Use all of themfor now
nohotdogs_sample = random.sample(other_urls, k=10000) # Let's get as many as we can without overunbalancing the classes
Let’s write them down so we don’t lose them, and we can use the lists from outside python some other day:
with open('hotdogs_sample.txt', 'w') as f:
f.write('\n'.join(hotdogs_sample))
with open('nohotdogs_sample.txt', 'w') as f:
f.write('\n'.join(nohotdogs_sample))
And that’s it! we have our images! More exactly, we have two lists of urls. That’s fine, because downloading them and setting them in the proper folder structure is a one-hour job. However, this post is long enough as it is, so I’ll show you how to do that next time.
Useful Links
http://image-net.org/synset?wnid=n07697537
http://www.image-net.org/api/text/imagenet.synset.geturls?wnid=n07697537
http://caffe.berkeleyvision.org/gathered/examples/imagenet.html