As a data scientist and the technical director of a master’s degree in data science, at this point I have participated, developed, and overseen a number of projects in the field.
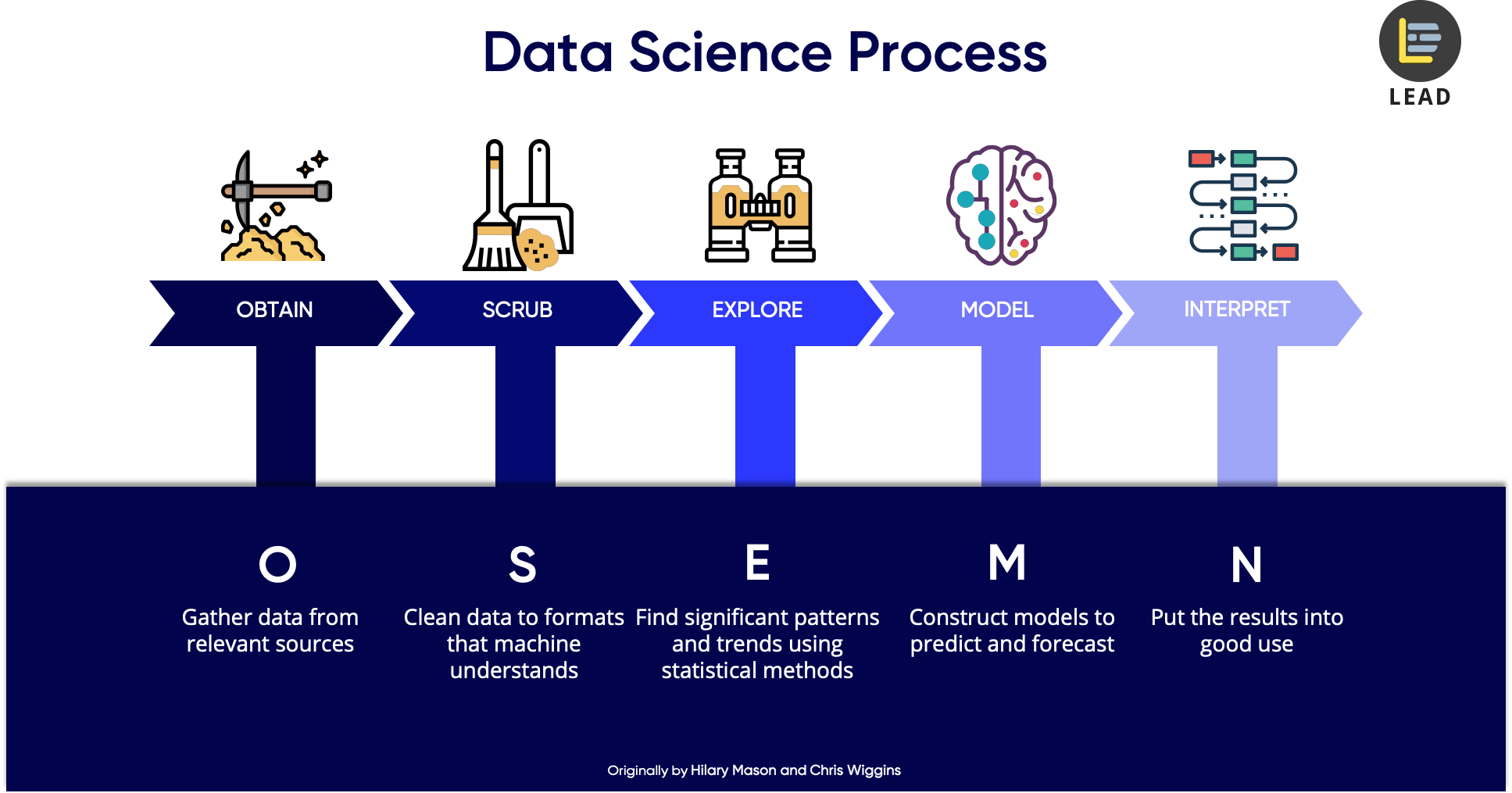
One pitfall that I have observed many people fall into is to plan a project so that the stages of the project correspond exactly to the steps the data goes through. That is: plan your project so that you spend 2 weeks looking for data, 2 weeks cleaning it, then 2 weeks exploring and visualizing, then 2 weeks modelling, and finally 2 weeks evaluating the model, summarizing, and preparing whatever presentation or frontend you must deliver at the end of the project.
It is very natural and obvious, which is why most newcomers to the field plan their projects like that, but suprisingly senior data scientists can make this mistake.
I say it’s a mistake because in my experience it invariably results in uneven projects and sloppy, unpolished deliverables due to huge wastes of time in parts of the project that turn out to be irrelevant.
You’ll start spending a looot of time polishing the data, imputing the missing values, and crafting clever and complicated features. You will almost surely spend more time than you planned on this, which will eat into the following stages, but the worst thing is that you have no way to measure whether your effort is improving the project!. You will most likely overkill, and by the time you realize the deadline is two weeks away, you’ll have to rush the parts of the project that are most visible to the target audience, be it a customer or someone inside your company.
I’ve seen many master’s thesis with great potential turn into middling projects because of this singular error.
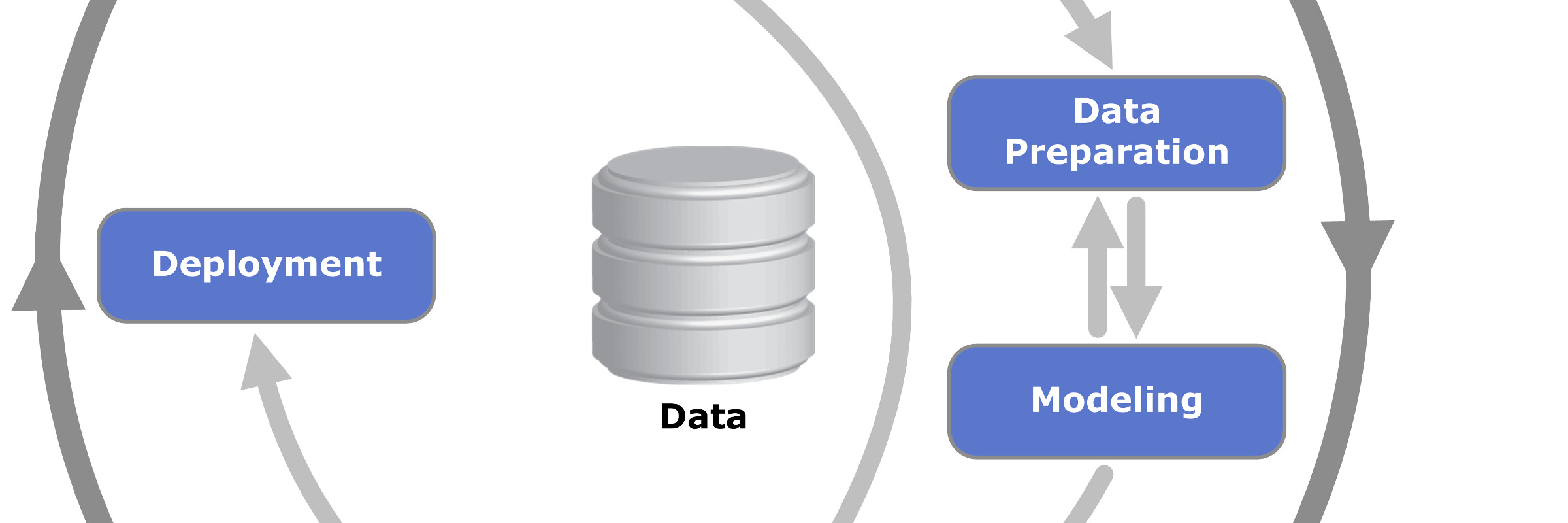
What I recommend my students is to plan their projects in an iterative way, very much like agile in software development. I tell them to build a quick and dirty prototype of the project as soon as they can. Very often it can take maybe three days and consist of a single Jupyter notebook with maybe twenty lines of code in which you load the data, discard nas, do a couple graphs and a linear or logistic regression.
Once you have this skeleton, this MVP, you are free to improve whatever part of the pipeline offers the most return for your time investment. Also, you will have a way to measure the impact of your efforts! The MVP provides a baseline against which to compare your model at each step of the process.
This also ensures, and this is particularly important in the context of a fixed deadline like a master’s thesis, that at any point you have a deliverable project. It will be shitty at the beginning and will improve over time, but it will be complete at every point.
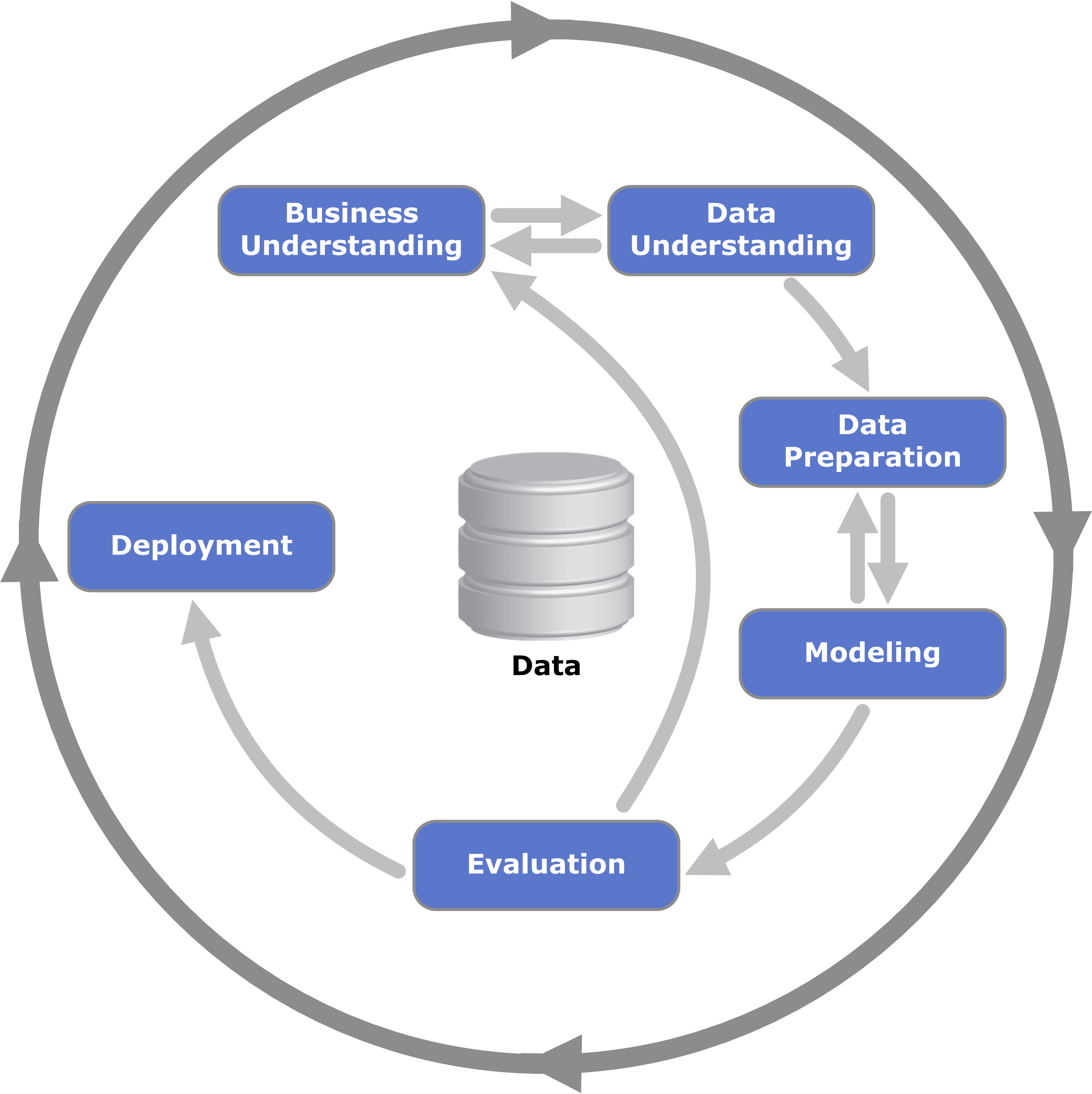
As far as I can tell, this is mostly what is described in the CRISP-DM methodology, which was developed in the late 1990s. It’s nothing new, but it still escapes a lot of people.
So, that’s my advice to everyone that undertakes a data science project. How do you handle yours? Do you think this is reasonable advice?