
On how choosing the right metrics can determine whether we build a decent hotdog detector or not.
![]()
Hi there! Welcome back! This is part 4 of a series on Deep Learning for image classification. In the three previous installments we learnt about imagenet and deep learning, the train-test split, and trained a first classifier than can tell hotdogs from nothotdogs with near 90% accuracy.
But wait! Now that I come to think of it, we have 120 hotdog images and 794 nohotdog images in our validation set, so a lazy classifier that assigns everything a ‘nothotdog’ label would get around 87% accuracy. Let’s check if that’s the case.
Recap
On the previous installment, we trained a first Convolutional Neural Network. In order to get to the same state, we need to either a) rerun the code in the same environment, or b) reload previously saved variables. In the interest of a self-contained tutorial, I’m just going to provide here the code to replicate the state we had at the end last time. If you want to understand this code, there is a lot of explanation there.
# Delete this line if you are not running the notebook in colab
%tensorflow_version 1.x
# Silence some annoying deprecation warnings
import logging
logging.getLogger('tensorflow').disabled = True
# Imports
import keras
from keras import backend as K
from keras.layers import Conv2D, MaxPooling2D, InputLayer, Flatten, Dense
from keras.optimizers import Adam
from keras.preprocessing.image import ImageDataGenerator
import os
# Download the data
!wget -q "https://www.dropbox.com/s/dhpekpce05iev6a/data_v2.zip?dl=0" -O data.zip
!rm -rf data/
!unzip -oq data.zip
!ls -lh data
# Design the net
my_first_cnn = keras.Sequential()
my_first_cnn.add(Conv2D(32, (3, 3), activation='relu', input_shape=(120, 120, 3)))
my_first_cnn.add(MaxPooling2D((2,2)))
my_first_cnn.add(Conv2D(32, (3, 3), activation='relu'))
my_first_cnn.add(MaxPooling2D((2,2)))
my_first_cnn.add(Flatten())
my_first_cnn.add(Dense(64, activation='relu'))
my_first_cnn.add(Dense(1, activation='sigmoid'))
# Data generators
base_dir = 'data//'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_datagen = ImageDataGenerator(rescale=1 / 255)
test_datagen = ImageDataGenerator(rescale=1 / 255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(120,120),
batch_size=100,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(120,120),
batch_size=100,
class_mode='binary')
# Compile and train
my_first_cnn.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-3),
metrics=['acc'])
history = my_first_cnn.fit_generator(train_generator,
steps_per_epoch=30,
epochs=10,
validation_data=validation_generator,
validation_steps=10)
# Save the model. If you did this last time, you could skip the training and do:
# from keras.models import load_model
# my_first_cnn = load_model('my_first_cnn.h5')
my_first_cnn.save('my_first_cnn.h5')
Using TensorFlow backend.
total 12K
drwxrwxr-x 4 root root 4.0K Jun 27 2018 test
drwxrwxr-x 4 root root 4.0K Jun 27 2018 train
drwxrwxr-x 4 root root 4.0K Jun 27 2018 validation
Found 4766 images belonging to 2 classes.
Found 888 images belonging to 2 classes.
Epoch 1/10
30/30 [==============================] - 25s 847ms/step - loss: 0.4540 - acc: 0.8761 - val_loss: 0.3445 - val_acc: 0.8725
Epoch 2/10
30/30 [==============================] - 17s 564ms/step - loss: 0.3084 - acc: 0.8715 - val_loss: 0.2995 - val_acc: 0.8664
Epoch 3/10
30/30 [==============================] - 17s 564ms/step - loss: 0.2687 - acc: 0.8783 - val_loss: 0.2625 - val_acc: 0.8785
Epoch 4/10
30/30 [==============================] - 17s 578ms/step - loss: 0.2435 - acc: 0.8706 - val_loss: 0.2504 - val_acc: 0.8684
Epoch 5/10
30/30 [==============================] - 17s 556ms/step - loss: 0.2404 - acc: 0.8763 - val_loss: 0.2496 - val_acc: 0.8735
Epoch 6/10
30/30 [==============================] - 17s 576ms/step - loss: 0.2147 - acc: 0.8783 - val_loss: 0.2570 - val_acc: 0.8664
Epoch 7/10
30/30 [==============================] - 17s 570ms/step - loss: 0.2162 - acc: 0.8755 - val_loss: 0.2481 - val_acc: 0.9231
Epoch 8/10
30/30 [==============================] - 17s 558ms/step - loss: 0.1953 - acc: 0.9013 - val_loss: 0.2358 - val_acc: 0.9028
Epoch 9/10
30/30 [==============================] - 17s 553ms/step - loss: 0.1793 - acc: 0.9166 - val_loss: 0.2437 - val_acc: 0.8811
Epoch 10/10
30/30 [==============================] - 14s 458ms/step - loss: 0.1826 - acc: 0.9083 - val_loss: 0.2338 - val_acc: 0.9109
Measuring performance
We are now ready to look deeper into the performance of our classifier.
Confusion matrix, precision and recall
The confusion matrix is a basic conceptual tool in binary classification. It’s just a matrix such that rows represent true classes and columns represent predicted classes.
Keras has assigned the label 0 to our hotdog class, which we consider positive, and 1 to our nothotdog class, which we consider negative. Therefore, in our binary classification setting we will have true positives top left, true negatives bottom right, false positives bottom left, and false negatives top right.
Therefore, precision will be
\[precision = \frac{true\ positives}{predicted\ positives} = \frac{C_{0,0}}{C_{0,0} + C_{1,0}}\]and recall will be:
\[recall = \frac{true\ positives}{total\ positives} = \frac{C_{0,0}}{C_{0,0} + C_{0,1}}\]%%time
validation_generator_noshuffle = test_datagen.flow_from_directory(validation_dir,
target_size=(120,120),
batch_size=100,
shuffle=False,
class_mode='binary')
validation_generator_noshuffle.reset()
predictions = my_first_cnn.predict_generator(validation_generator_noshuffle, steps=9)
predictions.shape
Found 888 images belonging to 2 classes.
CPU times: user 5.52 s, sys: 97.3 ms, total: 5.62 s
Wall time: 4.76 s
from sklearn.metrics import confusion_matrix
import seaborn as sns
%matplotlib inline
C = confusion_matrix(validation_generator_noshuffle.classes, predictions > .5)
ax = sns.heatmap(C, annot=True, square=True)
ax.set_ylabel('True class')
ax.set_xlabel('Predicted class')
precision = C[0,0] / (C[0,0] + C[1,0])
recall = C[0][0] / (C[0,0] + C[0,1])
print(precision, recall)
0.7704918032786885 0.41228070175438597
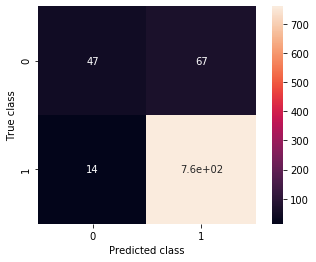
Oh. Right. That means that only 72% of our predicted hotdogs are such, and that we only detect around 50% of all the hotdogs in the dataset. That is, when our users get a “hotdog” prediction, the probability that they are pointing at a hotdog will be around 70%. Not awful, but definitely worse sounding than 90% accuracy. Moreover, the real problem is in the other metric, recall. That value means that when they point at a hotdog, the probability that the app recognizes it is only 50%! Not a great user experience. In short, our classifier is being way too cautious. It doesn’t risk a “hotdog” prediction very often, and therefore it is not wrong very often.
That illustrates a very important idea to keep in mind: choose the right metrics! Specially in unbalanced datasets, accuracy can be pretty misleading. We are fitting on binary cross entropy, which will naturally focus on getting right the most common class. You will have to think about what you want your model to focus on.
For example, in medical settings you will often have a very uncommon class (think VIH positive or breast cancer positive patients, both usually under 1%), and on top of that the error is asymmetrical: it is a lot worse to let a sick patient go than to tell a patient that they need might be sick and need to get more tests!! In that case, you’re more interested in maximizing recall even if precision suffers as a result.
In order to compensate for the fact that we have many more nothotdogs than hotdogs, fit_generator provides a class_weight parameter that allows us to artificially give more importance to underrepresented or specially important classes. Let’s try it:
%%time
from keras.optimizers import Adam
my_first_cnn.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-3),
metrics=['acc'])
history = my_first_cnn.fit_generator(train_generator,
class_weight = {0: 7, 1: 1},
steps_per_epoch=30,
epochs=10,
validation_data=validation_generator,
validation_steps=10)
Epoch 1/10
30/30 [==============================] - 18s 588ms/step - loss: 0.7615 - acc: 0.9260 - val_loss: 0.2623 - val_acc: 0.9069
Epoch 2/10
30/30 [==============================] - 17s 551ms/step - loss: 0.7168 - acc: 0.9367 - val_loss: 0.2481 - val_acc: 0.9049
Epoch 3/10
30/30 [==============================] - 17s 576ms/step - loss: 0.6823 - acc: 0.9187 - val_loss: 0.2570 - val_acc: 0.9049
Epoch 4/10
30/30 [==============================] - 17s 574ms/step - loss: 0.7019 - acc: 0.9413 - val_loss: 0.2498 - val_acc: 0.9089
Epoch 5/10
30/30 [==============================] - 17s 556ms/step - loss: 0.6453 - acc: 0.9446 - val_loss: 0.2746 - val_acc: 0.9221
Epoch 6/10
30/30 [==============================] - 17s 575ms/step - loss: 0.6328 - acc: 0.9483 - val_loss: 0.2505 - val_acc: 0.9119
Epoch 7/10
30/30 [==============================] - 17s 551ms/step - loss: 0.6235 - acc: 0.9460 - val_loss: 0.2502 - val_acc: 0.9018
Epoch 8/10
30/30 [==============================] - 17s 575ms/step - loss: 0.5921 - acc: 0.9466 - val_loss: 0.2561 - val_acc: 0.9170
Epoch 9/10
30/30 [==============================] - 17s 563ms/step - loss: 0.5640 - acc: 0.9553 - val_loss: 0.2617 - val_acc: 0.9109
Epoch 10/10
30/30 [==============================] - 13s 426ms/step - loss: 0.5668 - acc: 0.9550 - val_loss: 0.2562 - val_acc: 0.9190
CPU times: user 4min, sys: 5.91 s, total: 4min 6s
Wall time: 2min 46s
This time the confusion matrix is this one:
validation_generator_noshuffle.reset()
predictions = my_first_cnn.predict_generator(validation_generator_noshuffle, steps=9)
C = confusion_matrix(validation_generator_noshuffle.classes, predictions > .5)
ax = sns.heatmap(C, annot=True, square=True)
ax.set_ylabel('True class')
ax.set_xlabel('Predicted class')
precision = C[0,0] / (C[0,0] + C[1,0])
recall = C[0][0] / (C[0,0] + C[0,1])
print(precision, recall)
0.7029702970297029 0.6228070175438597
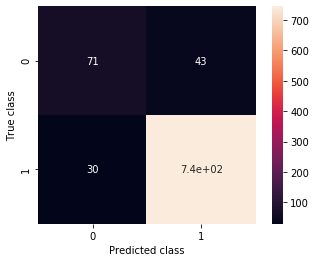
Much better! This won’t blow Jian-Yang away, but it’s a a lot better, despite having worse accuracy. Consider that before the previous notebook, you had no idea how to code a program to have some perception of the real world. Now you can!
Anyway, we have a classifier. It’s not great, but I’m sure it can get better. Let’s train it a bit more, shall we?
%%time
from keras.optimizers import Adam
my_first_cnn.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-3),
metrics=['acc'])
history_pt2 = my_first_cnn.fit_generator(train_generator,
class_weight = {0: 7, 1: 1},
steps_per_epoch=30,
epochs=20,
validation_data=validation_generator,
validation_steps=10,
verbose=1)
Epoch 1/20
30/30 [==============================] - 17s 583ms/step - loss: 0.5746 - acc: 0.9406 - val_loss: 0.2872 - val_acc: 0.8998
Epoch 2/20
30/30 [==============================] - 17s 564ms/step - loss: 0.5758 - acc: 0.9437 - val_loss: 0.2492 - val_acc: 0.9069
Epoch 3/20
30/30 [==============================] - 17s 553ms/step - loss: 0.5512 - acc: 0.9502 - val_loss: 0.2809 - val_acc: 0.8846
Epoch 4/20
30/30 [==============================] - 17s 577ms/step - loss: 0.5160 - acc: 0.9550 - val_loss: 0.2543 - val_acc: 0.9190
Epoch 5/20
30/30 [==============================] - 17s 571ms/step - loss: 0.5337 - acc: 0.9553 - val_loss: 0.2859 - val_acc: 0.9089
Epoch 6/20
30/30 [==============================] - 16s 542ms/step - loss: 0.5211 - acc: 0.9577 - val_loss: 0.2783 - val_acc: 0.8623
Epoch 7/20
30/30 [==============================] - 17s 563ms/step - loss: 0.5035 - acc: 0.9526 - val_loss: 0.2916 - val_acc: 0.9140
Epoch 8/20
30/30 [==============================] - 18s 588ms/step - loss: 0.4909 - acc: 0.9597 - val_loss: 0.2721 - val_acc: 0.9059
Epoch 9/20
30/30 [==============================] - 17s 558ms/step - loss: 0.4537 - acc: 0.9650 - val_loss: 0.2853 - val_acc: 0.9037
Epoch 10/20
30/30 [==============================] - 13s 428ms/step - loss: 0.4890 - acc: 0.9600 - val_loss: 0.2725 - val_acc: 0.8978
Epoch 11/20
30/30 [==============================] - 17s 578ms/step - loss: 0.4777 - acc: 0.9545 - val_loss: 0.2833 - val_acc: 0.9008
Epoch 12/20
30/30 [==============================] - 17s 582ms/step - loss: 0.4205 - acc: 0.9710 - val_loss: 0.2565 - val_acc: 0.9150
Epoch 13/20
30/30 [==============================] - 16s 544ms/step - loss: 0.4499 - acc: 0.9577 - val_loss: 0.3066 - val_acc: 0.8907
Epoch 14/20
30/30 [==============================] - 18s 588ms/step - loss: 0.4203 - acc: 0.9697 - val_loss: 0.2914 - val_acc: 0.9079
Epoch 15/20
30/30 [==============================] - 17s 551ms/step - loss: 0.4160 - acc: 0.9653 - val_loss: 0.2925 - val_acc: 0.8806
Epoch 16/20
30/30 [==============================] - 17s 554ms/step - loss: 0.4115 - acc: 0.9628 - val_loss: 0.2538 - val_acc: 0.8887
Epoch 17/20
30/30 [==============================] - 17s 568ms/step - loss: 0.4408 - acc: 0.9583 - val_loss: 0.2823 - val_acc: 0.8866
Epoch 18/20
30/30 [==============================] - 17s 564ms/step - loss: 0.3865 - acc: 0.9677 - val_loss: 0.2852 - val_acc: 0.9047
Epoch 19/20
30/30 [==============================] - 13s 434ms/step - loss: 0.3938 - acc: 0.9647 - val_loss: 0.2844 - val_acc: 0.9099
Epoch 20/20
30/30 [==============================] - 17s 554ms/step - loss: 0.4193 - acc: 0.9587 - val_loss: 0.2927 - val_acc: 0.8664
CPU times: user 7min 59s, sys: 10.9 s, total: 8min 9s
Wall time: 5min 31s
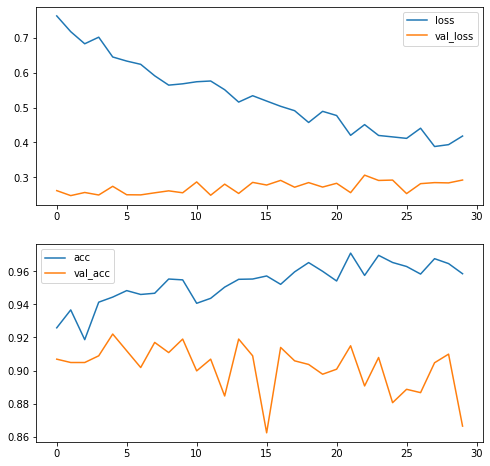
What’s happening here? We are seeing a typical case of overfitting. Our training loss is improving really fast, but at the same time the validation loss increases in each epoch. The network is learning the specific details of the training set, which don’t generalize all that well to the samples in the validation set.
We can appreciate that by plotting loss and validation loss over training. At some point, our loss keeps improving (going down), but validation loss keeps getting worse. The detector is getting hung up on the minor specificities of the training set.
%%time
import matplotlib.pyplot as plt
f, axes = plt.subplots(2,1)
f.set_size_inches(8,8)
nb_epochs = len(history.epoch)
concatenated = history.epoch + [nb_epochs + epoch_number for epoch_number in history_pt2.epoch]
axes[0].plot(concatenated, history.history['loss'] + history_pt2.history['loss'], label='loss')
axes[0].plot(concatenated, history.history['val_loss'] + history_pt2.history['val_loss'], label='val_loss')
axes[0].legend()
axes[1].plot(concatenated, history.history['acc'] + history_pt2.history['acc'], label='acc')
axes[1].plot(concatenated, history.history['val_acc'] + history_pt2.history['val_acc'], label='val_acc')
axes[1].legend()
CPU times: user 81.1 ms, sys: 2.05 ms, total: 83.1 ms
Wall time: 56.7 ms
The effect will be obvious if we check the confusion matrix on the validation set again. Remember, this is a classifier that gets over 95% of the items in the training set right!
%%time
validation_generator_noshuffle.reset()
predictions = my_first_cnn.predict_generator(validation_generator_noshuffle, steps=9)
C = confusion_matrix(validation_generator_noshuffle.classes, predictions > .5)
ax = sns.heatmap(C, annot=True, square=True)
ax.set_ylabel('True class')
ax.set_xlabel('Predicted class')
precision = C[0,0] / (C[0,0] + C[1,0])
recall = C[0][0] / (C[0,0] + C[0,1])
print(precision, recall)
0.5 0.7105263157894737
CPU times: user 5.31 s, sys: 84.1 ms, total: 5.39 s
Wall time: 4.49 s

And despite that super high accuracy, it’s not any better than the previous version. In fact, it’s worse.
This is the tightrope act that we must make all the time when practising Machine Learning: the bias-variance tradeoff. In short, that refers to the trade-off between flexibility and generality of the models. A sufficiently flexible (read: complicated) model will always be able to learn non-relevant details of the input dataset (to overfit), and Neural Networks are nothing if not complicated: notice above where we built our simple CNN: it has over $10^6$ parameters! That’s over a million knobs to tweak.
Overfitting means we have high variance: different samples will lead to very different estimations of the parameters. That will manifest as higher validation loss than training loss, as we see here from about epoch 8.
The solutions are simple but varied, and we need to keep many of them in our bag of tools for different occasions. Some are very general and some are pretty specific, but all of them fall under the heading of regularization. This is probably the best explanation of that that I’ve heard. In short, we want to penalize somehow the complexity of our models. That will in turn result in better generality.
In our specific example, image recognition, there’s one very intuitive way to make our model recognize more varied images of hotdogs: to feed it more varied images of hotdogs. Since we already collected as many as we could, what we can do is to generate more varied images of hotdogs.
And that is exactly what we’ll do in the next installment of this series.
Further Reading
Deep Learning with Python: A great introductory book by François Chollet, author of Keras. Explains the practice first, then goes down to theory.
Interview with François Chollet, author of DL with Python.
Implementing a Neural Network from scratch with Python: An in depth view of the internal architecture of a NN, with a tutorial to implement backpropagation.
Activation functions and their types: A nice discussion of activation functions.