![]()
Hi there!
Last time, we managed to get our hotdog detector to around 0.20 loss (binary cross entropy, a convenient loss measure for binary classification), which translated into 92% accuracy. But Jian-Yang is not yet happy- we won’t rest until we reach at least 95%!
We kind of reached the limits of our network but not quite. We could push it a bit more, but it would be no match for some networks out there pushed by the likes of DeepMind or OpenAI. These are industrial research labs with huge budgets. For example, a single training run of AlphaGo Zero, the more refined version of AlphaGo, has been estimated to cost millions of dollars! And you have to do scores of those while you are trail-or-error-ing your way to a useful network.
It would be great if we could take their work and not have to replicate it on our dime, wouldn’t it? Well, as you might have guessed, we can. Tobegin with, we can take their network architecture. That is the precise combination of layers they use. There are a bunch of famous architectures like for example AlexNet, the one that revolutionized the ImageNet competition, as I wrote about earlier.
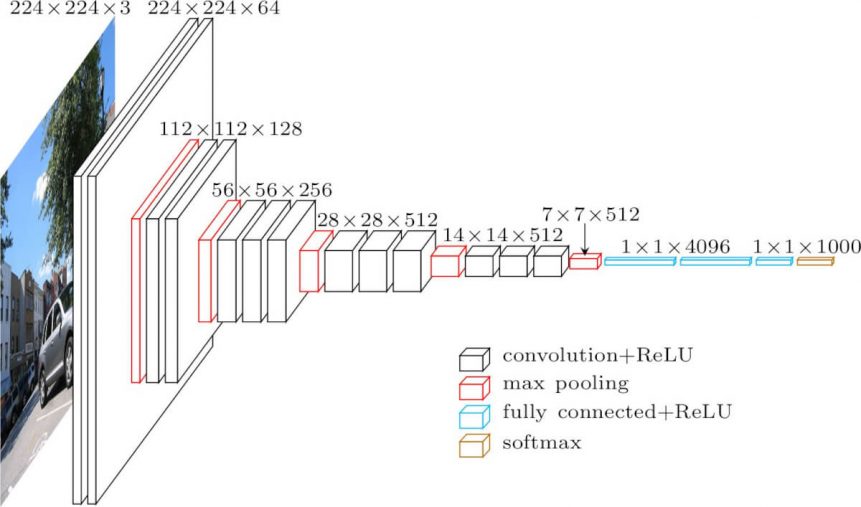
We are going to use VGG16, pictured above, just because it is quite better than ImageNet and it’s easily available within Keras, but there are far more powerful ones out there now.
What then?
Transfer Learning
The cool trick that allows us to use this huge net for our particular problem is called Transfer Learning and it’s actually really intuitive. Basically, we chop off the top of the net, then attach our own extension.
Remember in an earlier post in this series when I said that higher layers recognize increasingly elaborate features? Well, if we trained this network on the ~5500 images we have, it would have to learn to recognize even the most basic forms (straight lines, curves) from a very small set. With transfer learning, we take a network that has been pretrained on maybe millions of images and learnt to recognize very complex patterns and we keep only the most widely applicable part. Then, on the output of that, we attach a small easily trainable network.
# Delete this line if you are not running the notebook in colab
%tensorflow_version 1.x
# Silence some annoying deprecation warnings
import logging
logging.getLogger('tensorflow').disabled = True
import keras
from keras import backend as K
from keras.applications import VGG16
vgg = VGG16(weights='imagenet', # This will download the neuron weights
include_top=False,
input_shape=(120,120,3))
Using TensorFlow backend.
Notice that we want to freeze the pretrained part: the weights in the part that we attach are very far from optimum, while those under them are very close. If we let them change at the same learning rate as the top part, backpropagation is going to mean that the bottom weights “flay around” and the whole thing turns useless.
from keras.layers import Dense, Flatten
model = keras.Sequential()
vgg.trainable = False # Freeze VGG
model.add(vgg)
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 3, 3, 512) 14714688
_________________________________________________________________
flatten_1 (Flatten) (None, 4608) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 589952
_________________________________________________________________
dense_2 (Dense) (None, 128) 16512
_________________________________________________________________
dense_3 (Dense) (None, 64) 8256
_________________________________________________________________
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 15,329,473
Trainable params: 614,785
Non-trainable params: 14,714,688
_________________________________________________________________
Set up everything to train the classifier…
from keras.preprocessing.image import ImageDataGenerator
import os
# Download the data
!wget -q "https://www.dropbox.com/s/dhpekpce05iev6a/data_v2.zip?dl=0" -O data.zip
!rm -rf data/
!unzip -oq data.zip
!ls -lh data
# Download utility functions
!wget https://www.dropbox.com/s/qsyoi591pkltsvy/mateosio.py?dl=0 -O mateosio.py
base_dir = 'data/'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_datagen = ImageDataGenerator(rescale=1 / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1 / 255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size=(120,120),
batch_size=100,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(120,120),
batch_size=100,
class_mode='binary')
validation_generator_noshuffle = test_datagen.flow_from_directory(validation_dir,
target_size=(120,120),
batch_size=100,
shuffle=False,
class_mode='binary')
total 12K
drwxrwxr-x 4 root root 4.0K Jun 27 2018 test
drwxrwxr-x 4 root root 4.0K Jun 27 2018 train
drwxrwxr-x 4 root root 4.0K Jun 27 2018 validation
--2020-02-14 13:40:53-- https://www.dropbox.com/s/qsyoi591pkltsvy/mateosio.py?dl=0
Resolving www.dropbox.com (www.dropbox.com)... 162.125.8.1, 2620:100:601b:1::a27d:801
Connecting to www.dropbox.com (www.dropbox.com)|162.125.8.1|:443... connected.
HTTP request sent, awaiting response... 301 Moved Permanently
Location: /s/raw/qsyoi591pkltsvy/mateosio.py [following]
--2020-02-14 13:40:55-- https://www.dropbox.com/s/raw/qsyoi591pkltsvy/mateosio.py
Reusing existing connection to www.dropbox.com:443.
HTTP request sent, awaiting response... 302 Found
Location: https://ucdc4b53afe72a910331b5972fdc.dl.dropboxusercontent.com/cd/0/inline/AyFMRMCMEEVS40JICEH3aw4NxqgdQc23TZPvmM7mGVKshY2cD2Ms9DYBs8CBKqDeUHzWggCRFwZLN5CIraksuefFkjB4k7tznsMeLXjmRZWFC8efu16WVnNLBgJkAyg28fs/file# [following]
--2020-02-14 13:40:55-- https://ucdc4b53afe72a910331b5972fdc.dl.dropboxusercontent.com/cd/0/inline/AyFMRMCMEEVS40JICEH3aw4NxqgdQc23TZPvmM7mGVKshY2cD2Ms9DYBs8CBKqDeUHzWggCRFwZLN5CIraksuefFkjB4k7tznsMeLXjmRZWFC8efu16WVnNLBgJkAyg28fs/file
Resolving ucdc4b53afe72a910331b5972fdc.dl.dropboxusercontent.com (ucdc4b53afe72a910331b5972fdc.dl.dropboxusercontent.com)... 162.125.81.6, 2620:100:6031:6::a27d:5106
Connecting to ucdc4b53afe72a910331b5972fdc.dl.dropboxusercontent.com (ucdc4b53afe72a910331b5972fdc.dl.dropboxusercontent.com)|162.125.81.6|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1240 (1.2K) [text/plain]
Saving to: ‘mateosio.py’
mateosio.py 100%[===================>] 1.21K --.-KB/s in 0s
2020-02-14 13:40:55 (270 MB/s) - ‘mateosio.py’ saved [1240/1240]
Found 4766 images belonging to 2 classes.
Found 888 images belonging to 2 classes.
Found 888 images belonging to 2 classes.
We are set up! let’s train this.
from keras.optimizers import Adam
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-3),
metrics=['acc'])
history = model.fit_generator(train_generator,
class_weight = {0: 7, 1: 1},
steps_per_epoch=30,
epochs=30,
validation_data=validation_generator,
validation_steps=10)
Epoch 1/30
30/30 [==============================] - 32s 1s/step - loss: 0.8916 - acc: 0.7391 - val_loss: 0.3156 - val_acc: 0.8664
Epoch 2/30
30/30 [==============================] - 25s 831ms/step - loss: 0.7594 - acc: 0.8158 - val_loss: 0.2722 - val_acc: 0.9150
Epoch 3/30
30/30 [==============================] - 26s 865ms/step - loss: 0.6429 - acc: 0.8380 - val_loss: 0.2060 - val_acc: 0.9342
Epoch 4/30
30/30 [==============================] - 25s 848ms/step - loss: 0.6424 - acc: 0.8383 - val_loss: 0.2196 - val_acc: 0.9211
Epoch 5/30
30/30 [==============================] - 26s 857ms/step - loss: 0.5544 - acc: 0.8573 - val_loss: 0.2076 - val_acc: 0.9150
Epoch 6/30
30/30 [==============================] - 26s 859ms/step - loss: 0.5537 - acc: 0.8640 - val_loss: 0.2301 - val_acc: 0.9079
Epoch 7/30
30/30 [==============================] - 25s 847ms/step - loss: 0.5621 - acc: 0.8576 - val_loss: 0.2346 - val_acc: 0.8947
Epoch 8/30
30/30 [==============================] - 25s 837ms/step - loss: 0.5802 - acc: 0.8403 - val_loss: 0.2153 - val_acc: 0.9160
Epoch 9/30
30/30 [==============================] - 25s 838ms/step - loss: 0.5483 - acc: 0.8668 - val_loss: 0.1904 - val_acc: 0.9303
Epoch 10/30
30/30 [==============================] - 23s 762ms/step - loss: 0.5356 - acc: 0.8743 - val_loss: 0.1967 - val_acc: 0.9271
Epoch 11/30
30/30 [==============================] - 26s 861ms/step - loss: 0.4913 - acc: 0.8795 - val_loss: 0.2996 - val_acc: 0.8725
Epoch 12/30
30/30 [==============================] - 25s 838ms/step - loss: 0.5076 - acc: 0.8676 - val_loss: 0.1686 - val_acc: 0.9403
Epoch 13/30
30/30 [==============================] - 26s 868ms/step - loss: 0.5584 - acc: 0.8660 - val_loss: 0.2183 - val_acc: 0.9291
Epoch 14/30
30/30 [==============================] - 25s 845ms/step - loss: 0.5249 - acc: 0.8753 - val_loss: 0.1568 - val_acc: 0.9393
Epoch 15/30
30/30 [==============================] - 26s 859ms/step - loss: 0.5222 - acc: 0.8644 - val_loss: 0.2106 - val_acc: 0.9302
Epoch 16/30
30/30 [==============================] - 26s 863ms/step - loss: 0.5111 - acc: 0.8767 - val_loss: 0.2846 - val_acc: 0.8775
Epoch 17/30
30/30 [==============================] - 26s 855ms/step - loss: 0.4805 - acc: 0.8666 - val_loss: 0.2512 - val_acc: 0.8856
Epoch 18/30
30/30 [==============================] - 25s 832ms/step - loss: 0.4888 - acc: 0.8733 - val_loss: 0.1863 - val_acc: 0.9355
Epoch 19/30
30/30 [==============================] - 23s 769ms/step - loss: 0.4571 - acc: 0.8827 - val_loss: 0.1685 - val_acc: 0.9383
Epoch 20/30
30/30 [==============================] - 26s 871ms/step - loss: 0.4683 - acc: 0.8730 - val_loss: 0.2250 - val_acc: 0.9180
Epoch 21/30
30/30 [==============================] - 25s 843ms/step - loss: 0.4319 - acc: 0.8870 - val_loss: 0.2294 - val_acc: 0.8947
Epoch 22/30
30/30 [==============================] - 26s 862ms/step - loss: 0.5141 - acc: 0.8605 - val_loss: 0.3598 - val_acc: 0.8219
Epoch 23/30
30/30 [==============================] - 26s 860ms/step - loss: 0.5006 - acc: 0.8553 - val_loss: 0.2209 - val_acc: 0.9079
Epoch 24/30
30/30 [==============================] - 25s 837ms/step - loss: 0.4220 - acc: 0.8983 - val_loss: 0.2402 - val_acc: 0.9079
Epoch 25/30
30/30 [==============================] - 26s 868ms/step - loss: 0.4499 - acc: 0.8800 - val_loss: 0.2747 - val_acc: 0.8866
Epoch 26/30
30/30 [==============================] - 25s 848ms/step - loss: 0.4825 - acc: 0.8603 - val_loss: 0.1659 - val_acc: 0.9312
Epoch 27/30
30/30 [==============================] - 26s 852ms/step - loss: 0.4523 - acc: 0.8881 - val_loss: 0.2160 - val_acc: 0.9201
Epoch 28/30
30/30 [==============================] - 23s 767ms/step - loss: 0.5224 - acc: 0.8621 - val_loss: 0.1816 - val_acc: 0.9352
Epoch 29/30
30/30 [==============================] - 26s 871ms/step - loss: 0.4233 - acc: 0.8913 - val_loss: 0.1908 - val_acc: 0.9251
Epoch 30/30
30/30 [==============================] - 26s 880ms/step - loss: 0.3936 - acc: 0.8993 - val_loss: 0.1902 - val_acc: 0.9322
Well, it does seem promising, doesn’t it? Let’s see how it performs! Remember that we had around 45% precision 87% recall.
from mateosio import plot_confusion_matrix
%matplotlib inline
ax, precision, recall = plot_confusion_matrix(model, validation_generator_noshuffle)
print(precision, recall)
0.6624203821656051 0.9122807017543859
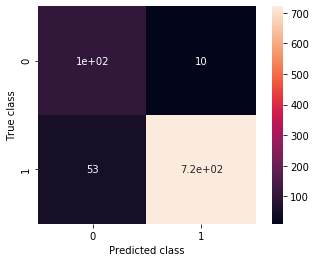
Wow! that’s quite the boost from something so simple, right? Well, what we did was simple, but it took advantage of the work of many smart people, and what they did was not that simple.
Now, we can keep training. We got a lot closer to the optimal weights, so it’s probably good to reduce the learning rate in order to fine tune rather than jump around the loss landscape.
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-4),
metrics=['acc'])
history_pt2 = model.fit_generator(train_generator,
class_weight = {0: 7, 1: 1},
steps_per_epoch=30,
epochs=30,
validation_data=validation_generator,
validation_steps=10)
model.save('vgg_frozen_convbase.h5')
Epoch 1/30
30/30 [==============================] - 28s 918ms/step - loss: 0.3849 - acc: 0.9015 - val_loss: 0.1811 - val_acc: 0.9332
Epoch 2/30
30/30 [==============================] - 26s 872ms/step - loss: 0.3896 - acc: 0.9073 - val_loss: 0.1831 - val_acc: 0.9322
Epoch 3/30
30/30 [==============================] - 26s 881ms/step - loss: 0.3923 - acc: 0.8977 - val_loss: 0.2100 - val_acc: 0.9200
Epoch 4/30
30/30 [==============================] - 26s 860ms/step - loss: 0.3822 - acc: 0.8933 - val_loss: 0.1831 - val_acc: 0.9332
Epoch 5/30
30/30 [==============================] - 26s 866ms/step - loss: 0.3888 - acc: 0.8988 - val_loss: 0.1725 - val_acc: 0.9312
Epoch 6/30
30/30 [==============================] - 25s 837ms/step - loss: 0.3975 - acc: 0.8925 - val_loss: 0.2150 - val_acc: 0.9140
Epoch 7/30
30/30 [==============================] - 25s 849ms/step - loss: 0.3662 - acc: 0.9083 - val_loss: 0.1973 - val_acc: 0.9221
Epoch 8/30
30/30 [==============================] - 26s 852ms/step - loss: 0.3971 - acc: 0.8903 - val_loss: 0.1935 - val_acc: 0.9231
Epoch 9/30
30/30 [==============================] - 26s 863ms/step - loss: 0.4128 - acc: 0.8968 - val_loss: 0.2205 - val_acc: 0.9078
Epoch 10/30
30/30 [==============================] - 23s 751ms/step - loss: 0.3678 - acc: 0.8980 - val_loss: 0.1822 - val_acc: 0.9332
Epoch 11/30
30/30 [==============================] - 26s 865ms/step - loss: 0.3685 - acc: 0.9066 - val_loss: 0.2209 - val_acc: 0.9200
Epoch 12/30
30/30 [==============================] - 27s 895ms/step - loss: 0.3337 - acc: 0.9147 - val_loss: 0.1674 - val_acc: 0.9342
Epoch 13/30
30/30 [==============================] - 27s 891ms/step - loss: 0.3538 - acc: 0.9098 - val_loss: 0.1923 - val_acc: 0.9362
Epoch 14/30
30/30 [==============================] - 27s 896ms/step - loss: 0.3971 - acc: 0.9111 - val_loss: 0.1862 - val_acc: 0.9362
Epoch 15/30
30/30 [==============================] - 26s 872ms/step - loss: 0.3839 - acc: 0.8980 - val_loss: 0.1933 - val_acc: 0.9221
Epoch 16/30
30/30 [==============================] - 26s 869ms/step - loss: 0.4016 - acc: 0.8861 - val_loss: 0.2062 - val_acc: 0.9150
Epoch 17/30
30/30 [==============================] - 26s 859ms/step - loss: 0.3359 - acc: 0.8960 - val_loss: 0.1817 - val_acc: 0.9352
Epoch 18/30
30/30 [==============================] - 26s 870ms/step - loss: 0.3713 - acc: 0.9070 - val_loss: 0.1750 - val_acc: 0.9395
Epoch 19/30
30/30 [==============================] - 23s 779ms/step - loss: 0.3642 - acc: 0.9051 - val_loss: 0.1915 - val_acc: 0.9231
Epoch 20/30
30/30 [==============================] - 26s 858ms/step - loss: 0.3605 - acc: 0.9046 - val_loss: 0.2100 - val_acc: 0.9170
Epoch 21/30
30/30 [==============================] - 26s 874ms/step - loss: 0.3814 - acc: 0.9063 - val_loss: 0.2186 - val_acc: 0.9160
Epoch 22/30
30/30 [==============================] - 26s 866ms/step - loss: 0.3573 - acc: 0.9057 - val_loss: 0.1951 - val_acc: 0.9221
Epoch 23/30
30/30 [==============================] - 26s 853ms/step - loss: 0.3556 - acc: 0.9041 - val_loss: 0.2237 - val_acc: 0.9170
Epoch 24/30
30/30 [==============================] - 26s 857ms/step - loss: 0.3219 - acc: 0.9090 - val_loss: 0.1731 - val_acc: 0.9403
Epoch 25/30
30/30 [==============================] - 25s 844ms/step - loss: 0.3495 - acc: 0.9106 - val_loss: 0.2164 - val_acc: 0.9130
Epoch 26/30
30/30 [==============================] - 27s 895ms/step - loss: 0.3299 - acc: 0.9100 - val_loss: 0.1956 - val_acc: 0.9291
Epoch 27/30
30/30 [==============================] - 25s 846ms/step - loss: 0.3311 - acc: 0.9151 - val_loss: 0.1915 - val_acc: 0.9293
Epoch 28/30
30/30 [==============================] - 23s 773ms/step - loss: 0.3516 - acc: 0.8993 - val_loss: 0.1790 - val_acc: 0.9302
Epoch 29/30
30/30 [==============================] - 26s 853ms/step - loss: 0.3274 - acc: 0.9124 - val_loss: 0.2173 - val_acc: 0.9160
Epoch 30/30
30/30 [==============================] - 27s 902ms/step - loss: 0.3274 - acc: 0.9050 - val_loss: 0.2028 - val_acc: 0.9180
ax, precision, recall = plot_confusion_matrix(model, validation_generator_noshuffle)
print(precision, recall)
0.6309523809523809 0.9298245614035088
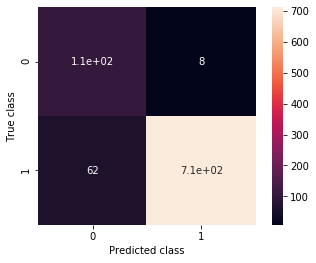
Notice that our model, now, has less free parameters than the original one: now we are only training the fully connected layers at the top. This improvement is wholly due to the convolutional filters in VGG16 having learned more useful features than our convolutional layers, even though they where trained for a (somewhat) different task!! Isn’t that cool?
In practice, my guess is that it’s both due to higher complexity in the convolutional base and many more training samples. Not to mention the experience and knowledge of the scientists that designed VGG! That’s what I meant by “standing on the shoulders of giants”. These guys spent years of their life, thousands of hours of work, and a lot of money and GPU time to train this network. Now we get it for free with little more than an import. Sometimes progress is awesome.
from mateosio import plot_training_histories
%matplotlib inline
plot_training_histories(history, history_pt2);
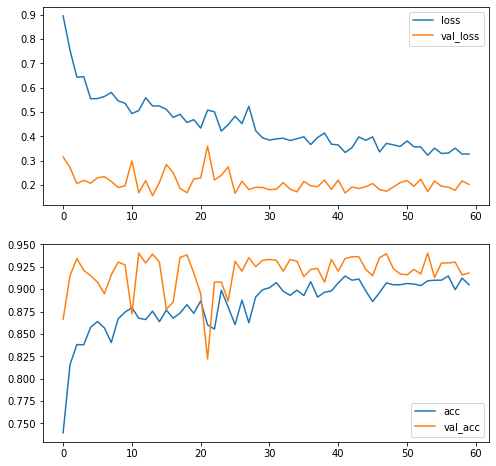
Fine Tuning
We can keep improving this if we fine tune the model to our purposes. We’ll only thaw the top part of VGG: the one that is marked as block 5.
# The VGG16 inside my model:
model.layers[0].summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 120, 120, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 120, 120, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 120, 120, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 60, 60, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 60, 60, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 60, 60, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 30, 30, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 30, 30, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 30, 30, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 30, 30, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 15, 15, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 15, 15, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 15, 15, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 15, 15, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 7, 7, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 7, 7, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 7, 7, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
for layer in model.layers[0].layers:
if 'block5' in layer.name:
layer.trainable = True
else:
layer.trainable = False
# Set the vgg as a whole to trainable:
model.layers[0].trainable = True
[layer.trainable for layer in model.layers[0].layers]
[False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
False,
True,
True,
True,
True]
Now we keep training the model. This time we will be updating the top few layers. We want to reduce the learning rate in order to keep them from ‘flailing around’
At first the loss and accuracy get worse, but they will start improving soon enough.
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-5),
metrics=['acc'])
history_pt2 = model.fit_generator(train_generator,
class_weight = {0: 7, 1: 1},
steps_per_epoch=30,
epochs=30,
validation_data=validation_generator,
validation_steps=10)
model.save('vgg_unfrozen_convbase_30epochs.h5')
Epoch 1/30
30/30 [==============================] - 29s 955ms/step - loss: 0.3110 - acc: 0.9158 - val_loss: 0.1765 - val_acc: 0.9352
Epoch 2/30
30/30 [==============================] - 27s 890ms/step - loss: 0.3614 - acc: 0.9033 - val_loss: 0.1775 - val_acc: 0.9241
Epoch 3/30
30/30 [==============================] - 27s 906ms/step - loss: 0.3365 - acc: 0.9147 - val_loss: 0.2080 - val_acc: 0.9251
Epoch 4/30
30/30 [==============================] - 26s 876ms/step - loss: 0.3089 - acc: 0.9243 - val_loss: 0.1638 - val_acc: 0.9453
Epoch 5/30
30/30 [==============================] - 26s 861ms/step - loss: 0.2928 - acc: 0.9178 - val_loss: 0.1972 - val_acc: 0.9261
Epoch 6/30
30/30 [==============================] - 27s 910ms/step - loss: 0.3262 - acc: 0.9187 - val_loss: 0.1640 - val_acc: 0.9393
Epoch 7/30
30/30 [==============================] - 26s 861ms/step - loss: 0.2823 - acc: 0.9303 - val_loss: 0.1931 - val_acc: 0.9251
Epoch 8/30
30/30 [==============================] - 27s 891ms/step - loss: 0.3316 - acc: 0.9203 - val_loss: 0.1898 - val_acc: 0.9271
Epoch 9/30
30/30 [==============================] - 26s 878ms/step - loss: 0.2583 - acc: 0.9300 - val_loss: 0.1743 - val_acc: 0.9324
Epoch 10/30
30/30 [==============================] - 23s 781ms/step - loss: 0.2563 - acc: 0.9330 - val_loss: 0.1423 - val_acc: 0.9453
Epoch 11/30
30/30 [==============================] - 26s 859ms/step - loss: 0.2689 - acc: 0.9293 - val_loss: 0.1894 - val_acc: 0.9352
Epoch 12/30
30/30 [==============================] - 27s 895ms/step - loss: 0.2253 - acc: 0.9413 - val_loss: 0.1571 - val_acc: 0.9403
Epoch 13/30
30/30 [==============================] - 26s 861ms/step - loss: 0.2406 - acc: 0.9426 - val_loss: 0.2328 - val_acc: 0.9180
Epoch 14/30
30/30 [==============================] - 27s 905ms/step - loss: 0.2085 - acc: 0.9447 - val_loss: 0.1443 - val_acc: 0.9484
Epoch 15/30
30/30 [==============================] - 27s 889ms/step - loss: 0.2399 - acc: 0.9420 - val_loss: 0.1529 - val_acc: 0.9433
Epoch 16/30
30/30 [==============================] - 26s 876ms/step - loss: 0.2128 - acc: 0.9421 - val_loss: 0.1496 - val_acc: 0.9443
Epoch 17/30
30/30 [==============================] - 27s 892ms/step - loss: 0.2326 - acc: 0.9428 - val_loss: 0.1314 - val_acc: 0.9514
Epoch 18/30
30/30 [==============================] - 26s 876ms/step - loss: 0.2449 - acc: 0.9353 - val_loss: 0.1546 - val_acc: 0.9457
Epoch 19/30
30/30 [==============================] - 23s 780ms/step - loss: 0.1847 - acc: 0.9508 - val_loss: 0.1491 - val_acc: 0.9464
Epoch 20/30
30/30 [==============================] - 27s 891ms/step - loss: 0.2289 - acc: 0.9475 - val_loss: 0.1559 - val_acc: 0.9393
Epoch 21/30
30/30 [==============================] - 27s 910ms/step - loss: 0.2020 - acc: 0.9503 - val_loss: 0.1724 - val_acc: 0.9453
Epoch 22/30
30/30 [==============================] - 26s 872ms/step - loss: 0.2027 - acc: 0.9523 - val_loss: 0.1332 - val_acc: 0.9494
Epoch 23/30
30/30 [==============================] - 26s 878ms/step - loss: 0.1957 - acc: 0.9537 - val_loss: 0.1954 - val_acc: 0.9302
Epoch 24/30
30/30 [==============================] - 27s 886ms/step - loss: 0.1897 - acc: 0.9507 - val_loss: 0.1355 - val_acc: 0.9534
Epoch 25/30
30/30 [==============================] - 27s 895ms/step - loss: 0.2010 - acc: 0.9498 - val_loss: 0.1395 - val_acc: 0.9443
Epoch 26/30
30/30 [==============================] - 27s 890ms/step - loss: 0.1714 - acc: 0.9550 - val_loss: 0.1370 - val_acc: 0.9585
Epoch 27/30
30/30 [==============================] - 26s 877ms/step - loss: 0.1923 - acc: 0.9535 - val_loss: 0.1690 - val_acc: 0.9436
Epoch 28/30
30/30 [==============================] - 24s 791ms/step - loss: 0.1765 - acc: 0.9480 - val_loss: 0.1572 - val_acc: 0.9413
Epoch 29/30
30/30 [==============================] - 28s 924ms/step - loss: 0.1420 - acc: 0.9622 - val_loss: 0.1370 - val_acc: 0.9605
Epoch 30/30
30/30 [==============================] - 27s 890ms/step - loss: 0.1418 - acc: 0.9657 - val_loss: 0.1562 - val_acc: 0.9433
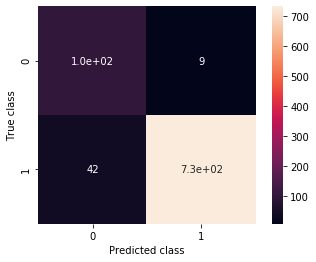
ax, precision, recall = plot_confusion_matrix(model, validation_generator_noshuffle)
print(precision, recall)
0.7142857142857143 0.9210526315789473
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-5),
metrics=['acc'])
history_pt3 = model.fit_generator(train_generator,
class_weight = {0: 7, 1: 1},
steps_per_epoch=30,
epochs=30,
validation_data=validation_generator,
validation_steps=10)
model.save('vgg_unfrozen_convbase_60epochs.h5')
Epoch 1/30
30/30 [==============================] - 28s 949ms/step - loss: 0.1602 - acc: 0.9630 - val_loss: 0.1335 - val_acc: 0.9575
Epoch 2/30
30/30 [==============================] - 26s 879ms/step - loss: 0.1326 - acc: 0.9653 - val_loss: 0.1490 - val_acc: 0.9575
Epoch 3/30
30/30 [==============================] - 27s 896ms/step - loss: 0.1569 - acc: 0.9613 - val_loss: 0.1319 - val_acc: 0.9585
Epoch 4/30
30/30 [==============================] - 26s 879ms/step - loss: 0.1525 - acc: 0.9670 - val_loss: 0.1294 - val_acc: 0.9575
Epoch 5/30
30/30 [==============================] - 26s 869ms/step - loss: 0.1776 - acc: 0.9550 - val_loss: 0.1558 - val_acc: 0.9545
Epoch 6/30
30/30 [==============================] - 27s 895ms/step - loss: 0.1574 - acc: 0.9623 - val_loss: 0.1535 - val_acc: 0.9565
Epoch 7/30
30/30 [==============================] - 27s 898ms/step - loss: 0.1575 - acc: 0.9590 - val_loss: 0.1409 - val_acc: 0.9555
Epoch 8/30
30/30 [==============================] - 27s 884ms/step - loss: 0.1523 - acc: 0.9642 - val_loss: 0.1348 - val_acc: 0.9555
Epoch 9/30
30/30 [==============================] - 26s 874ms/step - loss: 0.1578 - acc: 0.9628 - val_loss: 0.1341 - val_acc: 0.9621
Epoch 10/30
30/30 [==============================] - 24s 809ms/step - loss: 0.1236 - acc: 0.9700 - val_loss: 0.1769 - val_acc: 0.9413
Epoch 11/30
30/30 [==============================] - 27s 886ms/step - loss: 0.1925 - acc: 0.9501 - val_loss: 0.1063 - val_acc: 0.9626
Epoch 12/30
30/30 [==============================] - 27s 893ms/step - loss: 0.1612 - acc: 0.9680 - val_loss: 0.1677 - val_acc: 0.9453
Epoch 13/30
30/30 [==============================] - 27s 900ms/step - loss: 0.1368 - acc: 0.9692 - val_loss: 0.1338 - val_acc: 0.9504
Epoch 14/30
30/30 [==============================] - 26s 868ms/step - loss: 0.1159 - acc: 0.9693 - val_loss: 0.1761 - val_acc: 0.9443
Epoch 15/30
30/30 [==============================] - 27s 886ms/step - loss: 0.1218 - acc: 0.9698 - val_loss: 0.1046 - val_acc: 0.9626
Epoch 16/30
30/30 [==============================] - 27s 906ms/step - loss: 0.1413 - acc: 0.9680 - val_loss: 0.1749 - val_acc: 0.9534
Epoch 17/30
30/30 [==============================] - 26s 879ms/step - loss: 0.1205 - acc: 0.9708 - val_loss: 0.1620 - val_acc: 0.9474
Epoch 18/30
30/30 [==============================] - 27s 896ms/step - loss: 0.1235 - acc: 0.9690 - val_loss: 0.1676 - val_acc: 0.9518
Epoch 19/30
30/30 [==============================] - 24s 805ms/step - loss: 0.1151 - acc: 0.9700 - val_loss: 0.1688 - val_acc: 0.9545
Epoch 20/30
30/30 [==============================] - 26s 882ms/step - loss: 0.0943 - acc: 0.9787 - val_loss: 0.1148 - val_acc: 0.9656
Epoch 21/30
30/30 [==============================] - 27s 886ms/step - loss: 0.1188 - acc: 0.9705 - val_loss: 0.1778 - val_acc: 0.9514
Epoch 22/30
30/30 [==============================] - 27s 901ms/step - loss: 0.0832 - acc: 0.9787 - val_loss: 0.1802 - val_acc: 0.9545
Epoch 23/30
30/30 [==============================] - 26s 877ms/step - loss: 0.0745 - acc: 0.9795 - val_loss: 0.1075 - val_acc: 0.9696
Epoch 24/30
30/30 [==============================] - 26s 873ms/step - loss: 0.0852 - acc: 0.9772 - val_loss: 0.1743 - val_acc: 0.9545
Epoch 25/30
30/30 [==============================] - 27s 885ms/step - loss: 0.1636 - acc: 0.9648 - val_loss: 0.1806 - val_acc: 0.9605
Epoch 26/30
30/30 [==============================] - 27s 902ms/step - loss: 0.1093 - acc: 0.9715 - val_loss: 0.1249 - val_acc: 0.9656
Epoch 27/30
30/30 [==============================] - 26s 877ms/step - loss: 0.0853 - acc: 0.9823 - val_loss: 0.1396 - val_acc: 0.9559
Epoch 28/30
30/30 [==============================] - 24s 812ms/step - loss: 0.0917 - acc: 0.9780 - val_loss: 0.1445 - val_acc: 0.9545
Epoch 29/30
30/30 [==============================] - 27s 908ms/step - loss: 0.0882 - acc: 0.9767 - val_loss: 0.1080 - val_acc: 0.9706
Epoch 30/30
30/30 [==============================] - 26s 882ms/step - loss: 0.1033 - acc: 0.9733 - val_loss: 0.1584 - val_acc: 0.9585
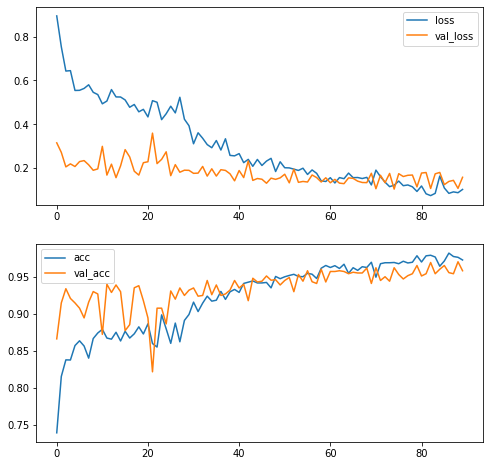
plot_training_histories(history, history_pt2, history_pt3);
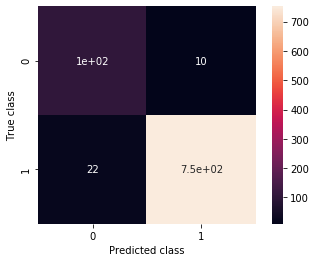
ax, precision, recall = plot_confusion_matrix(model, validation_generator_noshuffle)
print(precision, recall)
0.8253968253968254 0.9122807017543859
Well, we did manage to get us some of that sweet sweet overfitting, didn’t we? Notice how the training loss had gotten kind of stuck there until we lowered the learning rate.
In this case, unfreezing the top of the convolutional stack didn’t help us a lot, possibly because VGG16 was trained on ImageNet so the features it recognizes are already very applicable.
In any case, I feel that there is still some performance here that we can squeeze out. What do you say, we apply some more regularization so that we can train even more?? We’ll do that in the next part of this series.
Further Reading
Deep Learning with Python: A great introductory book by François Chollet, author of Keras. Explains the practice first, then goes down to theory.
DeepMind’s blog entry on AlphaGo Zero, the self-taught version of AlphaGo
Keras applications: pretrained models available within Keras